
做一个有温度和有干货的技术分享作者 —— Qborfy
今天我们来学习 卷积网络CNN
一句话核心:CNN = 模拟人类视觉系统,用
局部感知+参数共享机制高效处理图像、视频、医学影像等网格数据
简单理解就是将图片数据降低复杂度,在拆分成一个个小块(局部特征),结合统一的参数规划,最终完成图像识别。
是什么?
定义: 卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),是深度学习(deep learning)的代表算法之一 。由于卷积神经网络能够进行平移不变分类(shift-invariant classification),因此也被称为“平移不变人工神经网络(Shift-Invariant Artificial Neural Networks, SIANN)” 。
对比
传统神经网络痛点:
- 全连接参数爆炸(1000x1000图片 → 100万权重)
- 忽略空间局部性(远处像素强行关联)
CNN对比优势:
| 特性 | 全连接网络 | CNN卷积网络 |
|---|---|---|
| 参数量(1000x1000图) | 10^6 级 | 10^4 级(降99%) |
| 空间信息处理 | 破坏局部结构 | 保留局部特征关联 |
| 平移不变性 | 无 | 有(物体移动仍可识别) |
| 典型应用 | 结构化数据预测 | 图像/视频/医疗影像 |
CNN卷积网络的优势:
- 能够将大数据量的图片有效的降维成小数据量(并不影响结果)
- 能够保留图片的特征,类似人类的视觉原理
怎么做
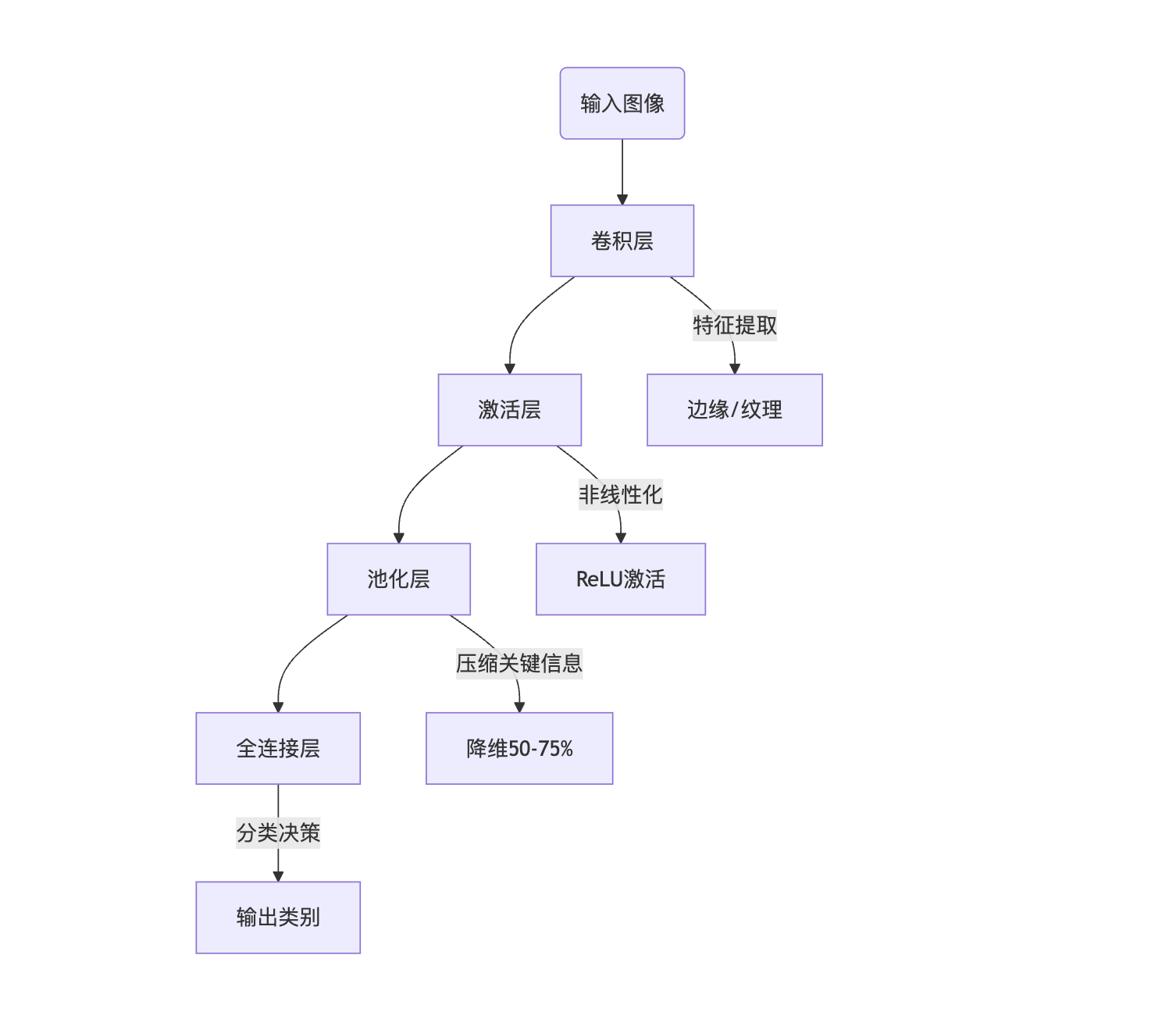
三层功能
- 输入层:接收数据(如28x28像素的手写数字图片)
- 隐藏层:层层提取特征(线条→局部图案→完整数字)
- 提取特征(卷积):卷积核(3x3像素)在图片上滑动,提取局部特征
- 池化(降维):缩小图片尺寸,减少参数量,防止过拟合
- 激活(非线性):防止过拟合,提升模型泛化能力
- 全连接:将提取到的特征组合起来,形成分类器
- 输出层:给出预测结果(概率最大的数字0-9)
卷积执行可视化: https://poloclub.github.io/cnn-explainer/
实际应用
- 图像分类:识别图片中的物体,如猫、狗、飞机、汽车等
- 目标检测:识别图片中的物体位置,如人脸、车辆、动物等
- 目标分割:识别图片中的物体位置和类别,如人、车、树、草等
- 人脸识别:识别图片中的人脸,如人脸验证、人脸检索等
- 图像生成:生成图片,如风格迁移、图像修复等
冷知识
- 深度CNN(如ResNet-152)中,仅15%卷积核激活显著,其余对输出贡献微弱。剪枝技术可删除冗余核,模型缩小90%,精度损失<1% —— 手机端CNN的部署基础
- 2016年击败李世石的AlphaGo,其策略网络实为13层CNN
参考资料


- 本文作者: Qborfy
- 本文链接: https://www.qborfy.com/ailearn/daily/06.html
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!
